Une décennie après l’arrivée du SAN, voilà que se profile une nouvelle ère, celle du Fichier ou plutôt du Réseau de Fichiers. De plus en plus important car critique pour l’entreprise, les données non-structurées, à priori les plus simples à créer, partager et échanger, progressent de plus de 80% par an et cristallisent aujourd’hui un vrai besoin chez les utilisateurs. Plusieurs analystes évoquent même comme priorité numéro 1 - 62% des réponses pour l'étude du Taneja Group pour en citer une - les projets de gestion de fichiers au sein des entreprises, focalisant ainsi une bonne partie des budgets des prochains trimestres. Les objectifs historiques du SAN se retrouvent ici avec l’idée de mutualiser et de consolider les espaces de stockage et de permettre une relation complète entre les utilisateurs et les unités de stockage hébergeant leurs données. Et comme par magie, l’industrie fête aussi les vingt ans du protocole NFS, créé par Sun Microsystems, tout ça pour arriver à l’unification de ces technologies pour en génèrer une troisième : la virtualisation de fichier. En fait, on le constate et le vit tous les jours, la simplicité de NFS et depuis quelques temps des services de fichiers NAS ont révolutionné les centres de données en offrant une très grande facilité d’installation, de gestion et d’accès pour les utilisateurs. Malgré tout, un vrai paradoxe est né car le phénomène a dépassé l’espérance. En effet, l’omniprésence et la multiplication de ces serveurs a engendré une complexité grandissante, gérer plus de 5 serveurs de fichiers, dédiés ou non, à fortiori s’ils sont de marques différentes devient de plus en plus délicat, difficile et soumis à une forte pression quant au service délivré. Néanmoins l’existant est là et doit continuer à satisfaire les utilisateurs dans la période d’investissement voulue. Ces derniers souhaitent un accès permanent et les administrateurs une capacité de gestion puissante mais surtout transparente pour les consommateurs de ces espaces de stockage. De ces besoins exprimés sont nées plusieurs tentatives, parmi lesquelles le Network File Management (NFM) ou le Network File Virtualization (NFV) poussés par plusieurs vendeurs.
De quoi s’agit-il ? L’idée est la
Virtualisation de Fichiers ou du Service de Fichiers pour s’affranchir des limites des systèmes de fichiers et des serveurs de fichiers existants et lever les quelques dernières obstructions à une adoption massive pour tout secteur et toute application. Tout comme son grand frère, la virtualisation mode bloc, celle orientée fichier s’efforce de masquer la complexité du stockage, de fournir une couche d’abstraction entre les clients « consommateurs » et les serveurs « producteurs » quant à la localisation des fichiers et des services associés. Ainsi les actions de gestion ou de production deviennent transparentes pour l’utilisateur, la relation rigide entre un fichier et sa résidence, le serveur et l’utilisateur, est « cassée ». Autrement dit, un fichier devient accessible par plusieurs chemins c’est-à-dire plusieurs serveurs sans que l’utilisateur ne s’en préoccupe et s’en aperçoive,
l’essentiel est l’accès au fichier.
Ainsi est né le
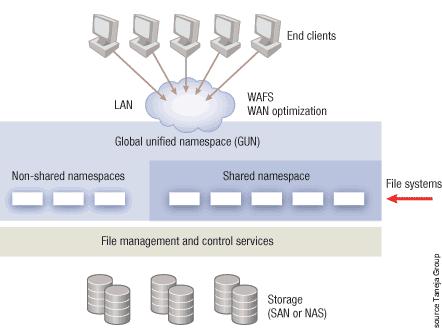
FAN – File Area Network – véritable sésame du stockage fichier aujourd’hui, qui est devenu le point d’ancrage et de convergence de l’industrie. Le FAN est le résultat de l’abstraction de la localisation et l’appartenance des fichiers aux serveurs de son nommage. Ainsi la visibilité extérieure du nommage du fichier donnée à l’utilisateur est différente de la réalité tout en conservant le contenu intact. Cette nouvelle tendance forte sur le marché se matérialise par l’ajout d’un composant, logiciel ou matériel, essentiel à la constitution d’un tel « réseau de fichiers », qui crée un espace global de nommage des fichiers (global namespace) issu de tous les serveurs présents dans l’environnement et participants à cette logique. Une « super » arborescence est établie, pour simplifier ici notre propos, agrégeant l’ensemble des espaces de stockage sous-jacents, on comprend alors aisément la facilité de navigation offerte à l’utilisateur par une telle approche. L’image ci-après illustre la visibilité offerte à l’utilisateur et l’agrégation complète des environnements fichiers.

La promesse du FAN, en conséquence, est de régler les soucis et problèmes de gestion des environnements fichiers surtout quand ceux-ci deviennent importants par le nombre de serveurs, souvent de marques et modèle différents, critiques quant à leur rôle dans le système d’information et également quand le réseau propose des déclinaisons très variées de systèmes de fichiers, quelque soit leur type : San, Cluster, Globaux, Distribués, Segmentés ou Parallèles, trouvant tous, une vocation à servir des fichiers pour le monde extérieur avec chacun des propriétés différentes et propres. L’existence même de toutes ces solutions au sein d’un réseau justifie l’adoption d’un FAN permettant de s’affranchir de vraies difficultés de gestion en offrant une interface simple et unifiée d’administration et surtout en permettant d’offrir des services additionnels, transparents pour les utilisateurs, comme la migration et la réplication de fichiers, la hiérarchisation de serveurs de fichiers, appelé aussi FLM pour File Lifecycle Management, l’équilibrage de charge entre serveurs, la protection de données ou tout simplement la consolidation logique d’espaces physiques.
Seuls cinq acteurs se distinguent sur le marché du FAN:
- Brocade, trés actif avec StorageX depuis l'acquisition début 2006 de NuView, seule offre logicielle et out-of-band du marché,
- Acopia Networks avec la famille ARX,
- Attune Systems, issu de Z-Force, avec son Maestro File Manager,
- Neopath Networks et son File Director, ces trois derniers étant positionnés in-band
- et le dernier de philosophie hybride out-band/in-band est l’offre Rainfinity Global File Virtualization d’EMC acquise mi-2005.
Toutes ces approches sont issues de startups et pour deux d’entre elles aujourd’hui intégrées au sein de sociétés matures et établies sur le marché. A croire que les gros acteurs ne devancent plus les demandes utilisateurs et font appel à de petites sociétés innovantes, prometteuses et surtout anticipatrices pour se renforcer par accords OEMs ou absorption pure et simple. Elles servent donc de laboratoire d’incubation des « bonnes nouvelles idées ». J’ose parier que les trois autres acteurs mentionnés seront d’ici 18 mois sous la coupe de vendeurs importants du secteur.
Revenons au détail des offres FAN, dans le monde in-band, un frontal est généralement placé « devant » les serveurs de fichiers et ainsi devient le passage obligé de toutes les requêtes les aiguillant vers le bon serveur. En cas de défaillance de ce frontal, il est toujours possible d’accéder au serveur directement puisqu’il n’y a pas de conversion ou de modification des informations sur l’unité de stockage. Dans le cas de l’out-band, un serveur particulier dit serveur de noms, non placé dans le chemin de données, constitue l’agrégation des serveurs de fichiers et fonctionne en dialogue avec les clients afin que ces derniers puissent accéder à la bonne ressource sans passer dans ce fameux serveur de noms. Cette approche est assez assimilable au serveur DNS indispensable au fonctionnement d’Internet.
En terme de système de fichiers, plusieurs approches se côtoient et peuvent exister au sein d’un FAN : les systèmes de fichiers en cluster (cluster file system), les SAN File System (systèmes de partage de fichiers sur un SAN), les systèmes de fichiers distribués, globaux et parallèles et autre WAFS (Wide Area File Services) en omettant volontairement l’existence d’instances unique de systèmes de fichiers c’est-à-dire de serveurs NAS isolés, appelés non-shared namespace dans l’image ci-dessus. Ces trois familles offrent toutes un espace de nommage partagé mais privé dont limité aux seuls serveurs mis en jeu dans cette configuration, le schéma nomme cette catégorie shared-namespace. Cette agrégation est réalisée de manière différente mais permet d’accéder et parcourir les arborescences de fichiers et systèmes de fichiers sans rupture ou saut entre les espaces de stockage sous-jacents.
Le monde du stockage bouge et cet axe de Stockage orienté Fichier est certainement un des plus attractifs du moment en terme de compétition vue les approches variées adoptées par les fournisseurs qui se concrétisent toutes par des succès commerciaux quotidiens. Il n’existe pas néanmoins de format universel mais les protocoles NFS et CIFS permettent de tirer parti de toutes les infrastructures de services fichiers mis en place. Le FAN promet donc de révolutionner l’administration et l’utilisation du monde fichier, sans alourdir la facture et les coûts associés. Encore une fois, l’utilisateur avait adopté une technologie de façon massive – le NAS pour simplifier –, les industriels n’avaient pas anticipé ce boom mais leur réaction, avec le FAN, répond aux conséquences de cette forte adoption garantissant une nouvelle fois la pérennité des investissements.


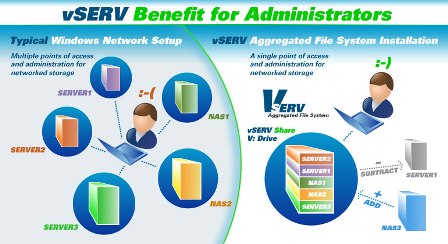
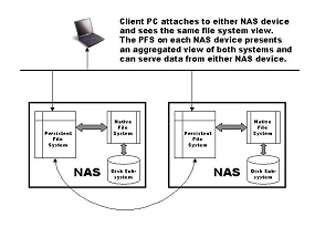 Aucun agent n'est nécessaire sur les clients, l'ensemble de la logique étant embarquée sur chaque serveur échangeant entre eux des données et notamment l'ensemble des meta-data répliqués entre tous les membres. La configuration repose essentiellement sur la définition d'un Aggregation Group (AG) défini par son nom, le share associé et le taux de remplissage en pourcentage - global à l'AG - pilotant le déplacement de fichiers entre les serveurs dans le cas où le taux d'occupation est atteint. Chaque système équipé de vSERV voit l'apparition d'une unité logique locale - V: - qui donne la même vision globale de l'agrégation des systèmes de fichiers mais en accès sur les serveurs composants l'ensemble. Ainsi chaque V: de serveur offre la même vue qui demeure identique pour l'utilisateur au travers du share global. Il peut être intéressant pour des raisons de performance de configurer un réseau dédié à la communication entre serveurs vSERV.
Aucun agent n'est nécessaire sur les clients, l'ensemble de la logique étant embarquée sur chaque serveur échangeant entre eux des données et notamment l'ensemble des meta-data répliqués entre tous les membres. La configuration repose essentiellement sur la définition d'un Aggregation Group (AG) défini par son nom, le share associé et le taux de remplissage en pourcentage - global à l'AG - pilotant le déplacement de fichiers entre les serveurs dans le cas où le taux d'occupation est atteint. Chaque système équipé de vSERV voit l'apparition d'une unité logique locale - V: - qui donne la même vision globale de l'agrégation des systèmes de fichiers mais en accès sur les serveurs composants l'ensemble. Ainsi chaque V: de serveur offre la même vue qui demeure identique pour l'utilisateur au travers du share global. Il peut être intéressant pour des raisons de performance de configurer un réseau dédié à la communication entre serveurs vSERV.